昨天那篇 OpenClaw 实战复盘发出去之后,后台留言和群里讨论最多的就是这几个方向的问题:Token 消耗、能干什么、本地模型、隐私安全、使用体验。今天挑出被问频率最高的五个,一个一个说清楚。

1. Token 消耗到底多少?贵不贵?
先说结论:没你想的那么贵,但也不是零成本。我前后用了两套方案,一套云端大厂套餐,一套国产性价比路线,感受差异还是挺明显的。
前期:OpenAI Pro 套餐(200 刀/月)
一开始接的是 OpenAI Pro,量大管饱,用着确实省心。不过这个套餐不是只给 OpenClaw 用的——我日常写代码也走这个额度,实际消耗大概一半一半。跑了段时间下来,5 小时速率上限从来没碰过,Weekly 上限也没撞到,说明我这种”重度使用但不是 7×24 不停歇”的用法,200 刀的额度是够用的。
后期:智谱 GLM5 Coding Plan(年费 ¥1608)
Pro 到期后,我切到了智谱 GLM5 Coding Plan,走的是国产模型路线。我买的时候赶上了首购优惠价 ¥980/年,但 **2026 年 2 月智谱调整了套餐价格,取消了首购优惠,整体涨幅约 30%**。
2026 年 3 月最新套餐价格
| 套餐 | 季费 | 年费(季费×4) | 月均 | 适用场景 |
|---|---|---|---|---|
| GLM Coding Lite | ¥132 | ¥528 | ¥44 | 轻度用户 |
| GLM Coding Pro | ¥402 | ¥1608 | ¥134 | 重度用户(推荐) |
| GLM Coding Max | ¥1266 | ¥5064 | ¥422 | 团队/企业 |
我用的相当于 Pro 档位,涨价前 ¥980/年,现在 ¥1608/年。实际跑下来体验还行,定时任务、巡检、日报周报、知识库整理这些高频场景都能稳稳撑住,没出现过限额不够用的情况。
GLM-5 API 按量计费(如果不用套餐)
如果你不想买套餐,也可以按量付费。GLM-5 的 API 价格:
| 模型 | 输入价格 | 输出价格 |
|---|---|---|
| GLM-5(0-32K) | ¥4 / 百万 Tokens | ¥18 / 百万 Tokens |
| GLM-5(32K+) | ¥6 / 百万 Tokens | ¥22 / 百万 Tokens |
| GLM-5-Code(0-32K) | ¥6 / 百万 Tokens | ¥28 / 百万 Tokens |
算笔账:我 7 天烧了 2.4 亿 Token,如果按量付费光这 7 天就要花大约 ¥2400,而套餐年费才 ¥1608——也就是说一整年的套餐价还不到 7 天按量费用的零头。所以我的建议很直接:重度用户直接上套餐,轻度用户可以先按量试试水深。
国内 Coding Plan 对比(2026 年 3 月)
这三家是对 OpenClaw 支持最好的国内模型:
| 套餐 | 智谱 GLM | MiniMax | Kimi |
|---|---|---|---|
| 入门档 | Lite ¥44/月(¥528/年) | Starter ¥70/月(¥700/年) | Moderato ¥133/月 |
| 进阶档 | Pro ¥134/月(¥1608/年) | Plus ¥140/月(¥1400/年) | Allegretto ¥99/月 |
| 高级档 | Max ¥422/月(¥5064/年) | Max ¥350/月(¥3500/年) | Vivace ¥199/月 |
| 主力模型 | GLM-5 | MiniMax M2.5 | Kimi K2.5 |
| 特点 | 国产最强,OpenClaw 默认支持 | 性价比高,API 稳定 | 长上下文强,2026 年转 token 计费 |
| OpenClaw 支持 | ⭐⭐⭐ 原生支持 | ⭐⭐⭐ 原生支持 | ⭐⭐ 需配置 |
我的选择是 GLM Coding Pro(¥1608/年),原因是 OpenClaw 对智谱的支持最成熟,API 稳定,中文能力强。性价比之选是 MiniMax Plus(¥1400/年),比 GLM Pro 便宜 200 块,能力接近。
⚠️ 以上价格为 2026 年 3 月查询结果,各家会不定期调整,购买前请以官网为准。
真实数据:7 天烧了 2.4 亿 Token
我查了下智谱后台:过去 7 天,GLM5 消耗了约 2.4 亿 Token。数字看起来挺吓人的,但要注意几点:这 2.4 亿是纯云端 GLM5 的消耗,本地模型处理的那部分并不算在里面;Coding Plan 年费 1608 元,2.4 亿 Token 分摊到 7 天的话平均每天大约 3400 万 Token;如果按量付费 GLM5 大约 0.01 元/千 Token,光这 7 天就要花 2400 元——而 Coding Plan 全年才 1608 元,套餐的性价比不言而喻。所以真实的费用结构是这样:云端干高质量任务,本地干高频脏活,搭配下来成本远没有想象中夸张。 完全不想花钱的话也可以只用本地模型起步,但能力上限和响应质量确实会差一截。如果愿意每月花一杯咖啡的钱接个云端模型,整体体验会好很多,尤其是长文写作和复杂推理的场景。
心态:别太功利
说到费用,我想多聊两句心态。养了这么久 OpenClaw(我家小朋友叫它”虾哥”),我最大的感触是:别一开始就想着变现、ROI 这些功利性的东西。AI 时代才刚刚开始,前期投资是必须的。你现在投入的时间和金钱可能暂时看不到直接收益,但会慢慢转化成你对 AI 能力边界的理解、对 Agent 协作的体感、对”什么场景能用 AI 解决”的直觉判断力。这些东西短期内没法量化,但长期来看价值巨大。
我的态度一直是:养虾就当给自己买了个大玩具,千金难买我开心。每天看它自己跑任务、写文章、整理知识库,这件事本身就已经很有成就感了。以后能变现当然好,但不能用”现在能不能变现”来决定要不要开始。先养起来,比什么都重要。
2. OpenClaw 到底能干什么?给几个实际的例子
上一篇实战复盘写得比较详细,但我知道很多人没耐心从头看到尾。这里直接捞几个我觉得最有价值、最能说明问题的场景出来。
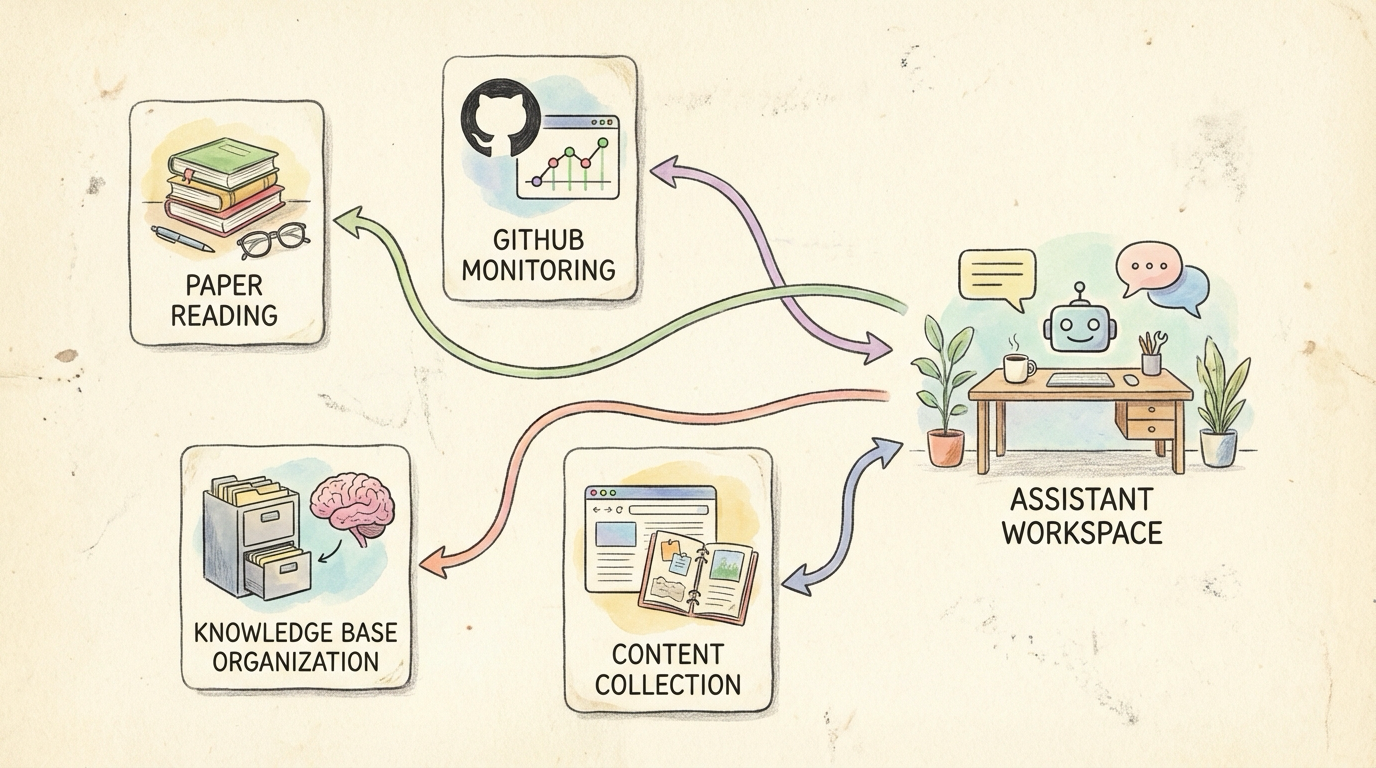
我正在用的
| 场景 | 说明 | 价值 |
|---|---|---|
| 每日论文精读 | 自动抓 Android/AI 论文 → 翻译 → 精读笔记,落盘到 Obsidian | 跟踪前沿,零人工 |
| GitHub 仓库监控 | 巡检 Issue/PR 变化,重要更新主动通知 | 我监控的是 Perfetto,不用每天刷 |
| 知识库建设 | 公众号/X/博客自动归档、结构化 | 1760 篇 Markdown 持续增长 |
| 内容回顾 | 每天推送值得重看的内容 | 解决”收藏了再也没看过” |
| Android 动态汇总 | 自动汇总领域动态,提取关键话题 | 不用刷信息流 |
核心价值在于,OpenClaw 最值钱的不是”帮你回答一个问题”,而是把那些你明知很重要、但凭意志力很难长期坚持的事情变成系统默认帮你执行的后台任务。
进阶案例 1:批量导入 NotebookLM 进行深度分析
NotebookLM 是 Google 推出的 AI 研究助手,可以把你的各种资料(PDF、网页、文档)变成一个可对话的知识库。它最大的亮点是能自动生成播客式音频概述——两个 AI 主持人用轻松聊天的形式帮你总结资料要点,通勤路上戴着耳机听非常香。但 NotebookLM 有个明显的痛点:手动添加资料很麻烦,需要一个一个上传文件、一条一条粘贴链接,资料一多就让人抓狂。OpenClaw 刚好可以帮你把这个流程自动化掉。
实际操作
1 | 我:帮我研究一下 Android 15 的性能优化特性。 |
OpenClaw 会自动搜集 Android 15 性能优化相关的官方文档、技术博客和论文,筛选掉水文和营销号只保留真正有价值的内容,然后通过 API 或浏览器自动化把资料一键导入 NotebookLM,最后触发播客生成。
为什么这个组合很香?
| 单独用 NotebookLM | OpenClaw + NotebookLM |
|---|---|
| 手动找资料、手动上传 | 自动搜集、批量导入 |
| 资料零散、质量参差不齐 | 筛选过的高质量来源 |
| 一个项目搞完就结束 | 可以定期更新、持续追踪 |
本质上就是把”信息搜集和筛选”这种费时费力的脏活外包给 OpenClaw,让 NotebookLM 专注于它最擅长的”深度分析和结构化输出”。
进阶案例 2:扔一个链接,自动抓取所有关联内容并落盘
这是我日常用得最多的场景之一,几乎每天都会触发。刷推或者看公众号的时候看到一篇好文章,里面提到了几篇论文、几个 GitHub 仓库、几个相关链接、几本推荐的书籍。以前的做法你一定不陌生:收藏 → 告诉自己回头看 → 忘记 → 再也没看过。现在有了 OpenClaw,做法变了:
1 | 我:https://example.com/awesome-article |
OpenClaw 会读取原文、识别所有链接和引用,然后分类处理:arXiv/论文链接下载 PDF 到 论文/ 目录,GitHub 链接判断是否值得 star、重要的克隆到本地,普通网页抓取正文转成 Markdown,书籍链接提取书名加入待读清单。最后生成一份包含原文摘要、所有关联内容链接和简介、落盘位置的索引 Markdown,自动保存到 Personal-Knowledge/source/ 目录。一个链接,一条指令,全套内容自动归位。 以后想回顾的时候打开 Obsidian 搜一下关键词就行,所有关联资料都已经按类型归好位了。
如果你是 Android 开发者
这是我目前还没做但正在规划中的方向,列出来看看有没有跟你产生共鸣的场景:
| 痛点 | OpenClaw 能做什么 | 适用 |
|---|---|---|
| Trace 分析门槛高 | 上传 Perfetto/Systrace → AI 辅助解读 → 生成”人话版”报告 | App 性能优化、系统 UX 性能 |
| 版本适配清单 | 自动抓 Android Release Notes → 生成适配 checklist → 对比代码标记检查点 | App 开发者(每年必做) |
| Issue 堆积难筛选 | 自动分类(bug/feature/question)→ 优先级判断 → 提取关键信息 | 开源维护者、团队协作 |
| Code Review 耗时 | 检测常见问题模式(空指针、资源泄漏、主线程 IO)→ 生成 Review checklist | 所有团队 |
| 技术债务遗忘 | 定期扫描 TODO/FIXME → 按优先级排序 → 定期提醒”该还债了” | 所有项目 |
| Benchmark 没人看 | 定期跑 benchmark → 自动对比历史 → 异常告警(启动 +500ms) | 性能优化团队 |
| 内部文档找不到 | 基于知识库回答”之前遇到过吗?””设计文档在哪?” | 所有团队 |
| 上游变更追踪 | 监控 AOSP/厂商代码变更 → 提醒需要合并的点 | 系统开发者 |
这些能力并不是开箱即用的,需要根据你自己的业务场景做定制开发。但 OpenClaw 的架构天然支持这些方向的扩展——关键是先把基础设施养起来,再根据实际需求慢慢迭代。
一句话总结
论文每天读、仓库每天盯、知识每天理、日报每天写。它真正做到的是,把”需要长期坚持”这件反人性的事情变成了”系统在后台默默帮你执行”。
3. 本地模型可以干什么?
本地模型的定位并不是替代云端大模型,而是专门负责那些脏活、累活和高频重复的任务。一句话概括分工:云端”想得深”,本地”跑得勤”。
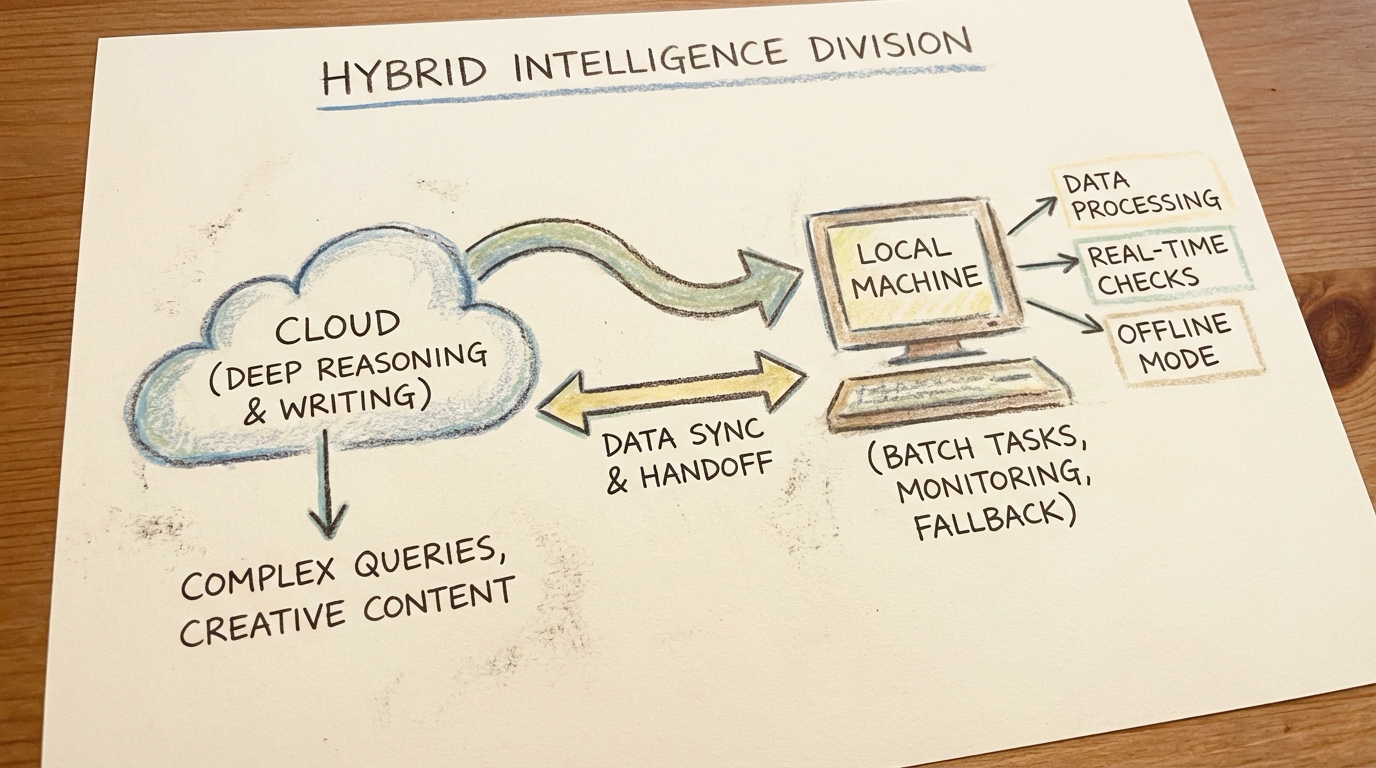
本地模型承担了多少?
我的实际运行数据:
| 任务类型 | 模型 | 占比 |
|---|---|---|
| 巡检、监控、批处理 | 本地 Qwen3.5-27B | 30% |
| 状态检查、轻量分类 | 本地 Qwen3.5-4B | 20% |
| 极轻任务 | 本地 Qwen3.5-2B | 10% |
| 云端失败降级 | 本地 Qwen3.5-9B | 5% |
| 长文、精修、复盘 | 云端 GLM5 | 15% |
| 日报周报、审计 | 云端 GLM5 | 10% |
| 论文精读、ClawFeed | 云端 GLM5 | 10% |
按任务数量算,本地承担了 60-70%;按 Token 消耗算,本地承担了 80%+。
我的配置
硬件是一台 Mac Studio(M 系列 Apple Silicon),上面部署了多个规格的本地模型:Qwen3.5-2B/4B/9B 使用 MLX 8bit 量化,负责轻量任务和云端故障时的容灾降级;Qwen3.5-27B 通过 Ollama 部署,承担高频结构化任务,是本地的主力干活模型。顺便提一句,Apple Silicon 上用 MLX 框架做推理的效率明显比 Ollama 高,尤其是跑小模型的时候差距更明显。
分工原则
| 本地适合 | 云端更强 |
|---|---|
| 高频结构化任务(RSS、队列处理) | 长文写作与精修 |
| 巡检与监控 | 复杂推理与判断 |
| 数据预处理(不离开本机) | 高质量翻译与解读 |
| 云端降级接管 | 论文精读、深度分析 |
至于成本,硬件本来就是已经购入的设备,电费增加也不多,所以本地模型的边际成本接近零。
烧 Token 的速度
即使有本地模型分担,云端 Token 还是烧得飞快。我的配置是主模型 GPT-5.4 + 干活主力 GLM5 + 本地苦力 Qwen3.5 系列(27B/9B/4B/2B)。所以我的建议是直接上量大管饱的 Coding Plan 套餐,预算充裕的话可以选 GPT Pro,追求性价比的话 MiniMax 或者 Kimi 都是不错的选择。按量付费的话,以这个消耗速度你一定会心疼的。
备用通道
虾哥前期运行偶尔会出现不稳定的情况,这时候我会用 Claude Code(Remote Control)远程连过去手动排查和救火。这种情况出现的频率不高,但有备用通道在手里心里踏实很多。
分工逻辑
打个比方,本地模型是”勤奋的蓝领工人”,云端模型是”聪明的高级顾问”。OpenClaw 做的事情就是帮你把这套分工协作的逻辑彻底自动化了。
4. 隐私和安全怎么保护?
这个问题被问得非常多,也确实是每个人在决定养虾之前必须认真想清楚的事情。
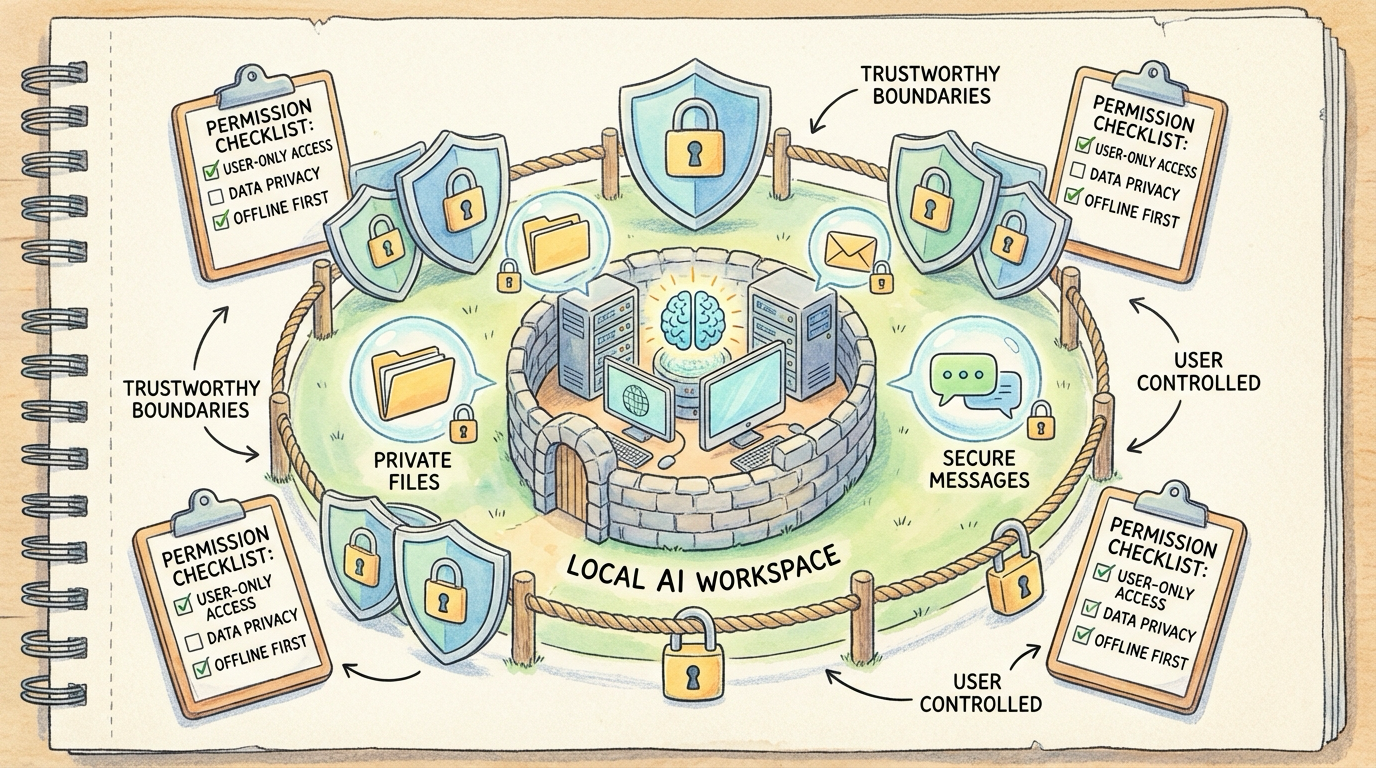
核心原则
敏感数据不离开本机。 这是我给自己划的底线。具体的做法也很简单直接:
- 敏感文件不上云端:公司代码、内部文档、个人隐私相关的内容,一律只走本地模型处理
- 本地优先:能在本地解决的任务,绝不走云端 API
- 最小权限原则:OpenClaw 只能访问我明确授权过的目录和工具,其他一概不给权限
技术层面的防护
命令执行白名单方面,safeBins 配置严格限制了它能执行的命令范围,只允许 ls、cat、grep、find、git 这些基础只读命令,而像 rm -rf 这样的危险操作会被 deniedFlags 直接拦截。也就是说即使有人尝试通过提示注入诱导它执行恶意操作,命令层面也根本跑不通。
来源校验方面,commands.ownerAllowFrom 和 channels.allowFrom 做了来源白名单,只允许我自己的账号发送系统级指令,即便在群聊里有其他人@它也不会响应任何敏感操作。
另外还有配置文件哈希校验,每天自动对 openclaw.json 生成 SHA256 哈希值并与基线值对比,一旦检测到配置文件被篡改系统会立刻触发告警通知。加上定期巡检,每天自动扫描 workspace 目录下的所有文件,检测是否存在私钥、密码、助记词等敏感信息,一旦发现就立即告警通知绝不静默忽略。
运行层面的隔离
- OpenClaw 跑在独立的 Mac Studio 上,不和我日常开发的机器混用
- 敏感账号(公司邮箱、内部系统)不接入 OpenClaw
- 微信公众号等对外发布渠道,只开放”草稿保存”,不开放”直接发布”
信任边界
我现在的策略是:OpenClaw 能看到的东西,不会比我主动发给云端 AI 的内容更敏感。 你想想看,日常用 ChatGPT、Claude 的时候也会上传文件、发截图,那些数据的暴露面其实更大、更不可控。OpenClaw 反而是相对受控的——它的权限范围、它的行为日志、它的所有操作记录全部都在我本地机器上,随时可以审计。
安全的本质
安全从来不是 AI Agent 自带的默认行为,而是需要你在部署之前主动设计和配置出来的。养虾之前先把笼子扎紧,这个顺序千万不能反。
5. 使用体验:手机随时操控,数据不会丢
这一条其实被问得不算多,但我个人觉得它是 OpenClaw 用起来真正”顺手”的关键所在,值得单独拎出来说说。

Telegram:一个主 bot + 若干群聊
我的用法是这样:主 bot 用私聊做日常对话、发指令、问问题;不同的 daily task 转发到不同的群——Android 群放技术简报、论文精读、GitHub 动态,Daily 群放日报、周报、系统通知,其他群按需分流。为什么要分群?原因有三个:
- 信息不混杂:技术内容和日常运维日志分开管理,想看哪个类别就进哪个群
- 通知可控:重要的群打开通知提醒,不重要的直接静音,避免信息轰炸
- 协作方便:有些群可以拉同事一起加入,共享信息源
数据落盘到 Obsidian
Telegram 在这个体系里只是”前端展示层”,真正重要的内容最终都会落盘到 Obsidian。这种架构设计意味着三件事:
- 不会丢:Telegram 的消息会随着时间被刷掉,但 Obsidian 里的 Markdown 文件会一直留存
- 可检索:Obsidian 的全文搜索能力远比 Telegram 的聊天记录搜索好用
- 可整理:后期可以随时对内容重新组织结构、打标签、建立双向链接
我现在 Obsidian 里的结构:
OpenClaw定时任务/:所有定时任务的输出论文/:论文精读三件套Personal-Knowledge/source/:知识库(1760 篇)X 文章/:归档的高价值 X 内容
手机随时访问
这一点的重要性比我最初想象的要大得多。出去玩的时候掏出手机打开 Telegram 就能直接给虾哥发指令,跟在电脑前操作没有区别;想看今天的日报打开 Obsidian 手机端文件已经通过 iCloud 同步过来了;遇到紧急情况需要调整任务也不用专门开电脑,手机上就能完成操作。我现在的日常习惯是早上醒来先刷一下 Telegram,看看昨晚虾哥跑了哪些任务、有没有异常,有问题的直接在手机上回复处理。外出的时候也能随时看一眼运行状态,心里有数。

架构总结
前端是 Telegram,后端是 Obsidian。 Telegram 解决的是”随时随地都能触达”的问题,Obsidian 解决的是”数据永远不会丢”的问题。两者结合在一起,才构成了一个真正好用的 24/7 全天候助手体验。
相关文章
关于我 && 博客
下面是个人的介绍和相关的链接,期望与同行的各位多多交流,三人行,则必有我师!
- 博主个人介绍 :里面有个人的微信和微信群链接。
- 本博客内容导航 :个人博客内容的一个导航。
- 个人整理和搜集的优秀博客文章 - Android 性能优化必知必会 :欢迎大家自荐和推荐 (微信私聊即可)
- Android 性能优化知识星球 : 欢迎加入,多谢支持~
一个人可以走的更快 , 一群人可以走的更远