/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key </tt>, or * <tt>null </tt> if there was no mapping for <tt> key</tt> . * (A <tt>null </tt> return can also indicate that the map * previously associated <tt>null </tt> with <tt> key</tt> .) */ public V put(K key, V value) { if (key == null) return putForNullKey(value); inthash= hash(key); inti= indexFor(hash, table .length ); for (Entry<K,V> e = table[i]; e != null; e = e. next) { Object k; if (e. hash == hash && ((k = e. key) == key || key.equals(k))) { VoldValue= e. value; e. value = value; e.recordAccess( this); return oldValue; } }
/** * Offloaded version of put for null keys */ private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e. next) { if (e. key == null) { VoldValue= e. value; e. value = value; e.recordAccess( this); return oldValue; } } modCount++; addEntry(0, null, value, 0); returnnull; }
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ voidaddEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && ( null != table[bucketIndex])) { resize(2 * table. length); hash = ( null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); }
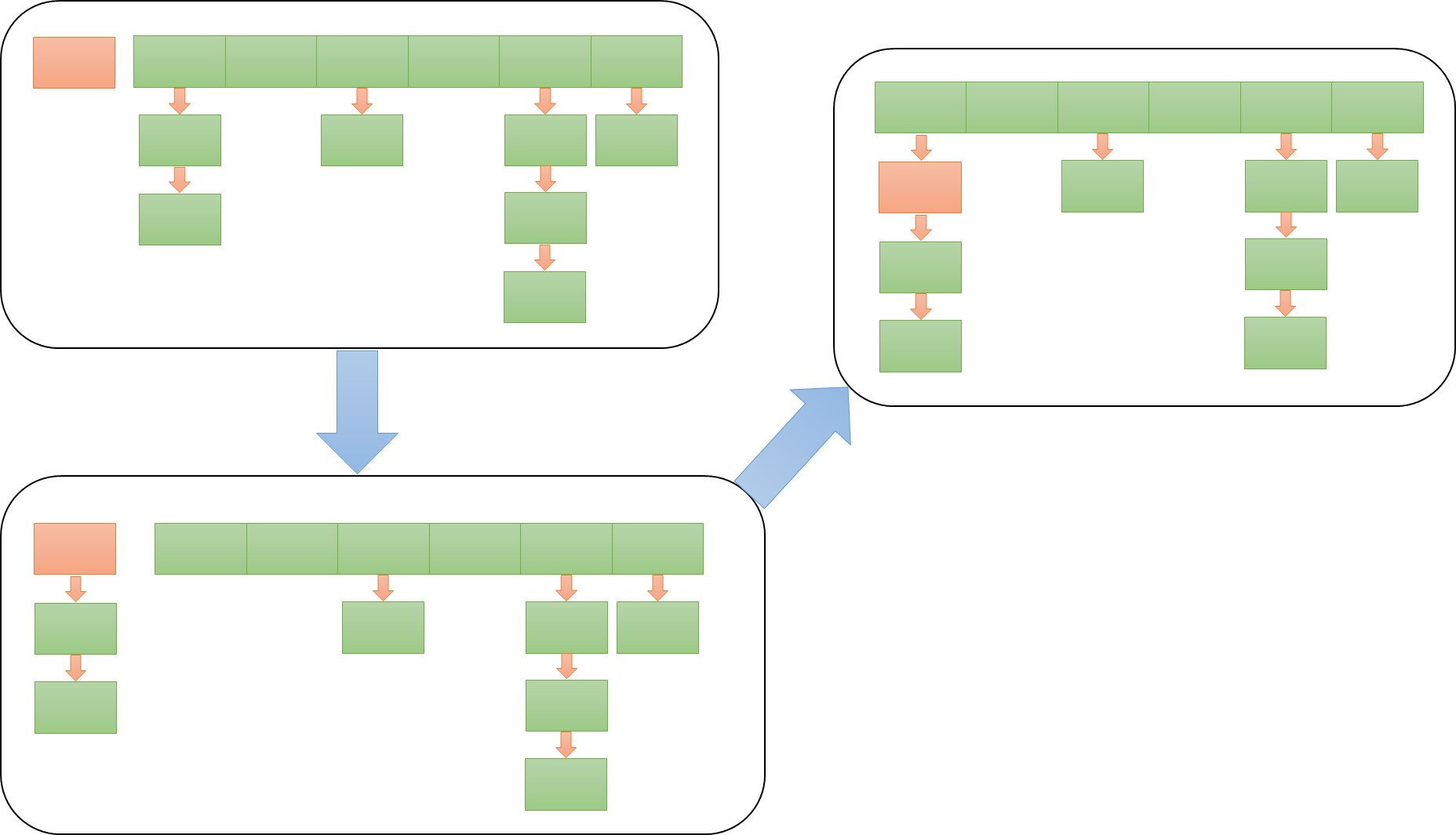
/** * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically when the * number of keys in this map reaches its threshold. * * If current capacity is MAXIMUM_CAPACITY, this method does not * resize the map, but sets threshold to Integer.MAX_VALUE. * This has the effect of preventing future calls. * * @param newCapacity the new capacity, MUST be a power of two; * must be greater than current capacity unless current * capacity is MAXIMUM_CAPACITY (in which case value * is irrelevant). */ voidresize(int newCapacity) { Entry[] oldTable = table; intoldCapacity= oldTable. length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer. MAX_VALUE; return; }
/** * Transfers all entries from current table to newTable. */ voidtransfer(Entry[] newTable, boolean rehash) { intnewCapacity= newTable. length; for (Entry<K,V> e : table) { while( null != e) { Entry<K,V> next = e. next; if ( rehash) { e. hash = null == e. key ? 0 : hash(e. key); } inti= indexFor(e.hash, newCapacity); e. next = newTable[i]; newTable[i] = e; e = next; } } }
/** * Like addEntry except that this version is used when creating entries * as part of Map construction or "pseudo -construction" (cloning, * deserialization). This version needn't worry about resizing the table. * * Subclass overrides this to alter the behavior of HashMap(Map), * clone, and readObject. */ voidcreateEntry( int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = newEntry<>(hash, key, value, e); size++; }
/** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * <p>More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code (key==null ? k==null : * key.equals(k))}, then this method returns {@code v}; otherwise * it returns {@code null}. (There can be at most one such mapping.) * * <p>A return value of {@code null} does not <i>necessarily </i> * indicate that the map contains no mapping for the key; it's also * possible that the map explicitly maps the key to {@code null}. * The {@link #containsKey containsKey} operation may be used to * distinguish these two cases. * * @see #put(Object, Object) */ public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key);
returnnull == entry ? null : entry.getValue(); }
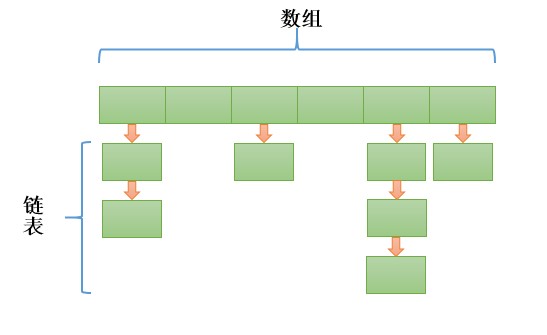
也是先判断key是不是null,做特殊处理。直接上代码,不赘述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/** * Offloaded version of get() to look up null keys. Null keys map * to index 0. This null case is split out into separate methods * for the sake of performance in the two most commonly used * operations (get and put), but incorporated with conditionals in * others. */ private V getForNullKey() { for (Entry<K,V> e = table[0]; e != null; e = e. next) { if (e. key == null) return e. value; } returnnull; }
/** * Returns the entry associated with the specified key in the * HashMap. Returns null if the HashMap contains no mapping * for the key. */ final Entry<K,V> getEntry(Object key) { inthash= (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[ indexFor(hash, table.length)]; e != null; e = e. next) { Object k; if (e. hash == hash && ((k = e. key) == key || (key != null && key.equals(k)))) return e; } returnnull; }
/** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail -fast. (See ConcurrentModificationException). */ transientint modCount;